
简介
s3fs(s3 fuse)是基于FUSE的文件系统,其使linux或Mac OS X有能力通过Fuse挂载到S3的一个bucket(桶)上,用户可以像操作本地文件系统一样操作S3的bucket.
案例使用
环境
| 名称 | 描述 |
|---|---|
| 操作系统 | CentOS Linux release 7.4.1708 |
| s3fs | v1.8.3 |
| s3 | 滴滴云对象存储 |
安装
- 安装依赖包
sudo yum install automake fuse fuse-devel gcc-c++ git libcurl-devel libxml2-devel make openssl-devel
- 编译源码安装
cd s3fs-fuse
./autogen.sh
./configure
make
sudo make install
使用
- 在用户主目录下创建.passwd-s3fs文件,用于存放秘钥
echo MYIDENTITY:MYCREDENTIAL > ~/.passwd-s3fs chmod 600 ~/.passwd-s3fs - 连接名为test-s3fs的Bucket
s3fs test /root/s3fs/s3fsmounttest -o passwd_file=/root/.passwd-s3fs -o url=http://s3.didiyunapi.com -d -o f2 -o allow_other -o umask=000如果想看打印日志可以运行如下命令:
-o dbglevel=info -f -o curldbg - 本地命令行ls显示文件状况
[root@hadoop1 s3fsmounttest]# ls indexFile.png techfoundation-109031601-281118-1847-2862.pdf test1
命令行参数
这里列出了部分命令及其描述
| option | 参数 | 描述 | |
|---|---|---|---|
| -h | 显示帮助 | ||
| -f | 打印出信息 | ||
| -o | use_cache= | 设置缓存目录 | |
| multireq_max= | 设置一个文件并行请求的最大线程数 | ||
| nomultipart= | 关闭大文件的并行请求 | ||
| passwd_file= | 指定passwd文件的路径 | ||
| multipart_size= | 设置并行请求中每次请求的文件长度,最小为5M | ||
| ensure_diskfree= | 确保缓存目录需要保留的磁盘空间 | ||
| dbglevel= | 设置日志的级别,silent、error、wan、inf、dbg |
机制分析
读取文件
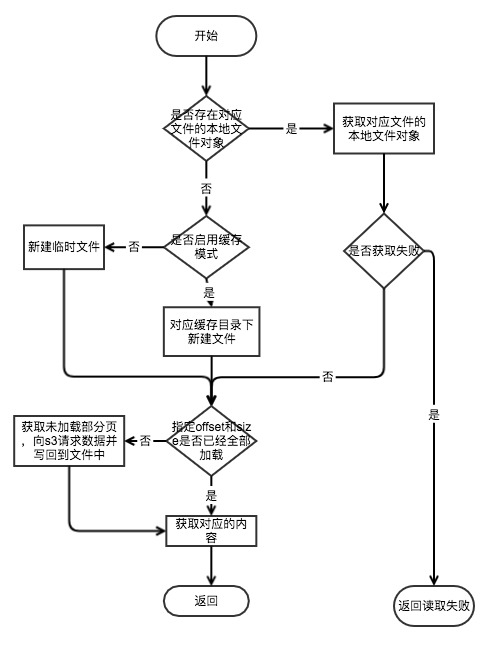
s3fs对于文件的存储分为临时文件和缓存两种方式,用户可以在命令行中通过use_cache参数指定缓存目录来启动缓存方式。用户通过offset和size来读取指定文件中的特定区域,如果本地没有相应的内容s3fs会通过网络请求S3上的相应内容,并且将对应的内容存储到本地的临时文件或者缓存中。
文件逻辑架构
不管是临时文件还是缓存文件,s3fs都用同一个逻辑架构组织这个文件,s3fs使用一个页的列表来代表一个文件,每页都是这个文件中的一部分,下图为对一个文件的逻辑组织架构。
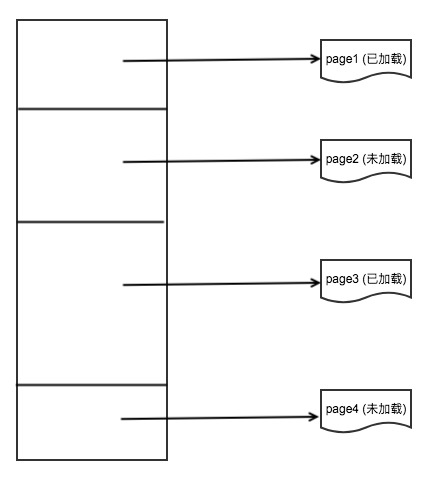
- fdpage fdpage代表了一个文件中的一页,即也是文件中的部分内容。
| 参数名 | 参数 |
|---|---|
| offset | 偏移量 |
| bytes | 页的大小 |
| bytes | 是否加载到了本地 |
- PageList PageList代表一个本地文件,它是fdpage的一个链表
| 参数名 | 参数 |
|---|---|
| pages | fdpage的链表 |
- FdEntity 对一个文件的全面描述,包括页链表、本地文件描述符、文件路径等
读取文件流程
读取文件流程图:
-
不启用缓存模式 不启用缓存模式下,s3fs会在本地新建一个临时文件来存储网络传送过来的数据,读取结束后关闭相应的句柄,这样做得好处是如果多个进程同时读取同一个文件就不需要频繁的发起网络请求。当这个临时文件的所有句柄都关闭后这个临时文件也会删除,具体的流程图如下。
-
启用缓存模式 启用缓存模式下,s3fs会将s3的数据在本地缓存一份,如果磁盘空间不够,s3fs会删除部分没有连接的文件来预留出磁盘空间。对于需要经常访问的文件,有一份在本地的缓存非常有必要。
读取文件网络请求流程
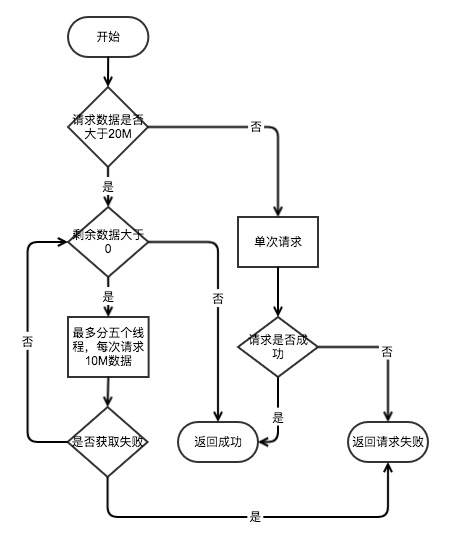
通过网络请求s3的数据,s3fs分为了两种,一种是单次请求,一种是多次请求,请求流程如下。
-
单次请求 默认情况下单次请求的大小在20M以下,s3fs会通过单个请求完成数据的请求。
-
多次请求 默认情况下如果请求的数据在20M以上,s3fs会切割数据进行多次请求,每次请求10M的数据,对单个文件的请求每次最多启动5个线程来进行数据的获取,并且是在5个线程都请求完成后才会启动下一轮请求。
尾记
转载请注明原地址,冯杰的博客:http://Lfengjie.github.io 谢谢!




