
etcd raft transport模块
etcd raft继承了简约的设计理念,只实现了最核心的raft算法, 节点之间数据的传输需要用户自己来实现,etcd自己使用的网络层库为transport。
简介
transport模块是etcd提供的raft网络库,其golang地址为”go.etcd.io/etcd/etcdserver/api/rafthttp”。 etcd-raft网络传输模块主要用于在一个raft集群的节点之间进行raft协议的消息传输,这里的消息包括raft协议中定义的所有消息类型,例如选主时的投票消息、日志复制消息、snapshot拷贝消息、集群节点变更消息等等。
如何使用transport
etcd的kv案例中就是使用transport作为raft的网络层,对于用户来说transport的使用比较简单。
- 初始化一个transport实例,官方案例如下:
- 需要传入本节点的id,clusterid等参数。
rc.transport = &rafthttp.Transport{ Logger: zap.NewExample(), ID: types.ID(rc.id), ClusterID: 0x1000, Raft: rc, ServerStats: stats.NewServerStats("", ""), LeaderStats: stats.NewLeaderStats(strconv.Itoa(rc.id)), ErrorC: make(chan error), } - 调用Start方法,并将raft集群中的其它节点的id和ip都加入到transport中 ``` rc.transport.Start()
for i := range rc.peers { if i+1 != rc.id { rc.transport.AddPeer(types.ID(i+1), []string{rc.peers[i]}) } }
- 需要调用Handler函数,这个函数会启动几个http的监听端口,用于在raft节点之间传输数据。
err = (&http.Server{Handler: rc.transport.Handler()}).Serve(ln)
至此就完成了transport的所有的准备工作。
2. 发送数据
transport.Send(Messages)
直接调用Send方法发送raftnode Ready方法返回的Messages数据。
3. 添加、删除节点
如果集群中间有节点的新增和删除,用户可以调用AddPeer和RemovePeer方法完成节点的新增和删除。
## 原理
transport主要分为raft消息的传输部分和节点存活的探针模块(对接prometheus),接下来主要着重讲raft节点之间的数据传输部分。
transport主要通过Peer子模块来实现节点之间的数据传输,transport会维护一个节点ID到Peer的map结构(peers)
transport的结构体如下:
type Transport struct { Logger *zap.Logger
DialTimeout time.Duration // maximum duration before timing out dial of the request
// DialRetryFrequency defines the frequency of streamReader dial retrial attempts;
// a distinct rate limiter is created per every peer (default value: 10 events/sec)
DialRetryFrequency rate.Limit
TLSInfo transport.TLSInfo // TLS information used when creating connection
ID types.ID // local member ID
URLs types.URLs // local peer URLs
ClusterID types.ID // raft cluster ID for request validation
Raft Raft // raft state machine, to which the Transport forwards received messages and reports status
Snapshotter *snap.Snapshotter
ServerStats *stats.ServerStats // used to record general transportation statistics
// used to record transportation statistics with followers when
// performing as leader in raft protocol
LeaderStats *stats.LeaderStats
// ErrorC is used to report detected critical errors, e.g.,
// the member has been permanently removed from the cluster
// When an error is received from ErrorC, user should stop raft state
// machine and thus stop the Transport.
ErrorC chan error
streamRt http.RoundTripper // roundTripper used by streams
pipelineRt http.RoundTripper // roundTripper used by pipelines
mu sync.RWMutex // protect the remote and peer map
remotes map[types.ID]*remote // remotes map that helps newly joined member to catch up
peers map[types.ID]Peer // peers map, 维护集群节点的map结构
pipelineProber probing.Prober
streamProber probing.Prober } ```
发送数据
transport调用Send方法来发送数据到其它节点
Send(m []raftpb.Message)
// raftpb.Message的proto 数据格式
message Message {
optional MessageType type = 1 [(gogoproto.nullable) = false];
optional uint64 to = 2 [(gogoproto.nullable) = false];
optional uint64 from = 3 [(gogoproto.nullable) = false];
optional uint64 term = 4 [(gogoproto.nullable) = false];
optional uint64 logTerm = 5 [(gogoproto.nullable) = false];
optional uint64 index = 6 [(gogoproto.nullable) = false];
repeated Entry entries = 7 [(gogoproto.nullable) = false];
optional uint64 commit = 8 [(gogoproto.nullable) = false];
optional Snapshot snapshot = 9 [(gogoproto.nullable) = false];
optional bool reject = 10 [(gogoproto.nullable) = false];
optional uint64 rejectHint = 11 [(gogoproto.nullable) = false];
optional bytes context = 12;
}
在raftpb.Message中的To字段会标识出这条信息需要发送到节点的ID,具体的实现还是通过调用Peer子模块中的Send方法。 数据的发送有两个方法:
-
streamWriter 顾名思义,这个方法是流式的向特定节点发送数据。streamWriter分成了msgAppV2Writer和writer,但是两个实例的处理流程都一样,只不过处理的数据类型不一样,msgAppV2Writer专门处理MsgApp类型,writer处理其它类型。不清楚为什么要分为两种情况,感觉一个流式实例就能处理完成了。
-
pipeline 每次请求都单独发送一个http数据包,主要用于用户发送快照数据,并在streamWriter无效的时候作为备选方案用来发送数据。
下图为选择的流程图:
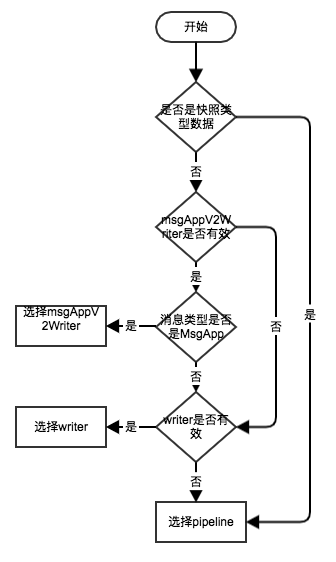
返回的其实是一个通道,peer将数据传入到指定的通道中,streamWriter和pipeline会从通道中获取并发送数据。
pipeline详解
pipeline的运行模式如下图:
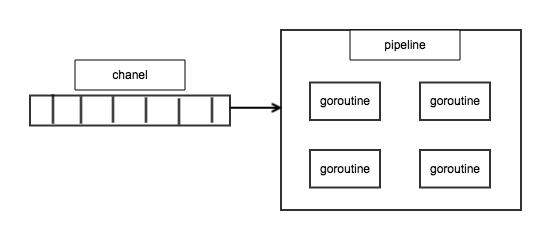
pipeline会启动四个协程,竞争的从msgc队列中获取数据发送(post发送),通道的buffer size为64。
streamWriter详解
streamWrite跟pipeline一样,也是从通道中获取数据发送,只是steamWriter会保持与目标机器的一个流式链接。 streamWrite会从四个channel中获取数据:
-
heartbeatc: 获取心跳数据并发送。
-
msgc: 普通需要发送的数据,包括:快照数据、日志数据等。
-
connc: 链接通道,这个通道会通知steamWriter有新的流式链接可以使用,这个时候streamWriter会替换新的io.Writer, 以后的数据就通过这个新的流式链接发送。
-
stopc: 通知关闭这个流式链接
streamWrite发送每条数据时都会在数据的最前端加上这段数据size,这样接收端就能通过这个size获取指定大小的数据,不会造成数据的误取。 如何获取得到这个streamWriter在后续的章节中会介绍
接收数据
每个raft节点都会启动一个http的server端用于接收数据,在使用的时候需要用户手动的去启动这个http server。 暴露了如下四个接口:
-
pipeline Handler: 用于接收pipeline方式发送过来的数据,path为/raft。
-
stream handler: 用于接收stream发送过来的数据,路径为: /raft/stream
-
snap handler: 用于接收pipeline发送快照时的数据,/raft/snapshot
-
probing handler: 用于接收探活请求,/raft/probing
streamReader
程序会循环的从流式连接中读取数据,每次读取都先获取这段数据的size,然后才根据size获取指定大小的数据解析。 只有在获取数据出错时程序才会尝试去获取新的streamReader,这样能保证一条连接的数据一定是可以读取完成的。解析完成后的数据会塞入到一个channel中,peer会开启一个协程不断的从这个channel中获取数据,并把数据交给raft node处理。
go func() {
for {
select {
case mm := <-p.recvc:
if err := r.Process(ctx, mm); err != nil {
if t.Logger != nil {
t.Logger.Warn("failed to process Raft message", zap.Error(err))
} else {
plog.Warningf("failed to process raft message (%v)", err)
}
}
case <-p.stopc:
return
}
}
}()
// r.Process might block for processing proposal when there is no leader.
// Thus propc must be put into a separate routine with recvc to avoid blocking
// processing other raft messages.
go func() {
for {
select {
case mm := <-p.propc:
if err := r.Process(ctx, mm); err != nil {
plog.Warningf("failed to process raft message (%v)", err)
}
case <-p.stopc:
return
}
}
}()
streamWrite和streamReader的获取
可能大家一定会好奇,transport中的streamWrite和streamReader怎么来的。上面讲到过,用户在使用transport的时候需要启动一个http server来处理请求。transport就使用这条链接的reader和writer来做流式写入和读取。例如A节点请求B节点, 这个时候就会把A节点的io.reader作为A节点的streamReader, 把B节点的response Writer作为streamWriter, 双方都不会主动的去关闭这条链接。所以etcd raft节点在启动时,节点之间就会主动发起请求来建立一条流式的连接。
监控
transport使用一个探针不断的去探测节点是否可达,探测的方式就是简单的调用被检测节点的get方法,如果有正常返回就认为节点可达,并把数据同步给监控模块。
尾记
转载请注明原地址,冯杰的博客:http://Lfengjie.github.io 谢谢!




