
总体介绍
版本介绍
代码主要基于 ceph 12,中间有部分改动,但是主体流程和代码不变
ObjectStore
ObjectStore是Ceph OSD中最重要的概念之一,它封装了对底层存储具体的IO操作。读请求会通过ObjectStore提供的API获得相应的内容,写请求也会利用ObjectStore提供的事务API将所有写操作组合成一个原子事务提交给ObjectStore。ObjectStore通过接口对上层提供不同的隔离级别,目前PG层采用了Serializable级别,保证同一个PG内读写的顺序性。 ObjectStore主要接口分为三部分,第一部分是Object的读写操作,类似于POSIX的部分接口,第二部分是Object的属性(xattr)读写操作,这类操作的特征是kv对并且与某一个Object关联。第三部分是关联Object的kv操作(在Ceph中称为omap),这个其实与第二部分非常类似,但是在实现上可能会有所变化。
FileStore
FileStore是ObjectStore的重要的实现之一(bluestore也是ObjectStore实现的其中一种),利用文件系统的POSIX接口实现ObjectStore API。每个Object在FileStore层会被看成是一个文件,Object的属性(xattr)会利用文件的xattr属性存取,但是有些文件系统(如Ext4)对xattr的长度有限制。omap一般使用levelDB来实现存储。为了缩小写事务的处理时间,提高写事务的处理能力并且实现事务的原子性,FileStore引入了FileJournal。所有写事务在被FileJournal处理以后都会立即返回。FileJournal类似于数据库的writeahead日志,使用O_DIRECT和O_DSYNC每次同步写入到journal文件,完成后该事务会被塞到FileStore的op queue。事务通常有若干个写操作组成,当在中间过程进程crash时,journal给OSD recover提供了完备的输入。FileStore会存在多个thread从op queue里获取op,然后真正apply到文件系统上对应的Object(Buffer IO)。当FileStore完成一个op后,对应的Journal可以丢弃这部分日志。实际上并不是所有的文件系统都按照这个顺序,一般来说如Ceph推荐的Ext4和XFS文件系统会先写入Journal,然后再写入Filesystem,而COW(Copy on Write)文件系统如Btrfs和ZFS会同时写入Journal和FileSystem。
FileStore总体介绍
代码位置
FileStore的主题代码在ceph的 src/os 下,这其中不仅有filestore的代码,还有bluestore、kstore等的代码。通过ObjectStore向上层提供统一的调用接口,如果你想在ceph中编写自己的存储只需要继承ObjectStore,并遵循一定的规则即可。
代码层次
下图为filestore中主要类的继承层次。
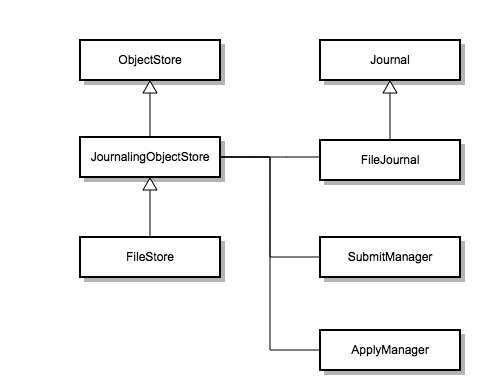
上图为filestore简单的类继承图:
- ObjectStore: 这是ceph底层对象存储向上提供接口的统一类,如果需要添加自己的存储引擎就需要继承这个类
- JournalingObjectStore: Filestore实现的基类,其中包含了一些具体的逻辑
- Filestore: 实现Filestore具体逻辑的类
- Journal: FileJournal的接口类
- FileJournal: Filestore中wal日志逻辑的具体实现
上层应用自己选择实例化不同的store,统一的调用 ObjectStore::create 方法通过传入不同的参数来完成底层存储的初始化。
写流程介绍
写流程总体介绍
操作语义:
- submit: 提交到journal队列
- apply: 写文件系统page cache
- commit: 将文件系统page cache数据fsync到磁盘
大体流程:
- FileStore::queue_transactions -> OSD上层调用该方法将写请求传递到ObjectStore这一层,objectStore也有同名的方法,如果是filestore的话最后会调用到该方法。
- JournalingObjectStore::_op_journal_transactions -> 该方法会调用journal的submit_entry方法将已经准备好的数据传入filejournal的writeq队列中
- FileJournal::write thread -> filejournal初始化时会自动启动一个写线程,该线程主要负责从writeq队列中获取相关entry并写入到日志中。该线程的入口函数为: FileJournal::write_thread_entry
- FileJournal 写入后回调: 如果是 libaio 写入的话,采用轮询机制调io_getevents来检查op的完成情况,check_aio_completion检查当前完成的连续的最大序列号,然后调 queue_completions_thru 给 client 返回写入成功,所以它是按照提交journal的顺序来给client返回操作成功
- FileStore::ondisk -> 这是journal落盘的回调,由上层应用传入,标志写成功,但数据不可读。在函数执行时这个回调会封装到C_JournaledAhead这个类中,日志落盘后会自动将回调抛入到回调队列中等待回调。由FileStore::ondisk_finisher相关线程进行回调
- FileStore::queue_op -> 将 op 抛入到具体的 OpSequencer(pg顺序写的保证) 中,等待op_tp线程的写入。
- FileStore::op_tp -> 这是一个线程池,入口函数为 FileStore::_do_op ,主要用于apply数据到文件系统的page cache,但不保证落盘
- FileStore::op_finisher -> apply文件系统完成的回调,标志数据可读
- FileStore::sync thread -> sync文件系统的内容到磁盘,将序列号通知journal,使得journal可以释放空间,重复利用
备注一下,这里的commit指sync线程将page cache的数据sync到data disk的意思,不是journal的disk。容易引起误解的地方是,osd_op_tp在提交事务的时候, 会有两个回调,一个是ondisk(客户端可以认为是on commit),表示数据已经落盘,因为journal一般采用O_DIRECT + O_DSYNC方式,写journal成功就表示数据落盘, 可以调用ondisk回调,通知客户端写成功,所以journal能改善写的性能,将随机转化为顺序,并且多个写可以合并成一次journal的写。 另外一个是onreadable,表示数据可读,在FileStore::op_tp线程池将数据写入page cache后,就可以读数据,可以调用onreadable回调
源码分析
- 入口函数:上层调用 queue_transactions 这个方法将op传入到filestore来,开启filestore的写流程,首先将数据传入到filejournal中
int FileStore::queue_transactions(CollectionHandle& ch, vector<Transaction>& tls,
TrackedOpRef osd_op,
ThreadPool::TPHandle *handle)
{
Context *onreadable;
Context *ondisk;
Context *onreadable_sync;
.......
// OpSequencer非常关键,同一个PG会使用同样的OpSequencer,保证PG操作串行化
OpSequencer *osr = static_cast<OpSequencer*>(ch.get());
dout(5) << __FUNC__ << ": osr " << osr << " " << *osr << dendl;
ZTracer::Trace trace;
if (osd_op && osd_op->pg_trace) {
osd_op->store_trace.init("filestore op", &trace_endpoint, &osd_op->pg_trace);
trace = osd_op->store_trace;
}
if (journal && journal->is_writeable() && !m_filestore_journal_trailing) {
Op *o = build_op(tls, onreadable, onreadable_sync, osd_op);
//prepare and encode transactions data out of lock
bufferlist tbl;
int orig_len = journal->prepare_entry(o->tls, &tbl);
.......
if (m_filestore_journal_parallel) {
......
} else if (m_filestore_journal_writeahead) { // ext4, xfs都需要wal
dout(5) << __FUNC__ << ": (writeahead) " << o->op << " " << o->tls << dendl;
osr->queue_journal(o); // journal层面的sequence记录在OpSequencer中的journal queue中, JournalingObjectStore::finisher线程中会deque_journal
.....
// 提交OP,注意这里的callback是ondisk,也就是一旦数据落入journal后就认为数据落盘了,不过还不可读而已
_op_journal_transactions(tbl, orig_len, o->op,
new C_JournaledAhead(this, osr, o, ondisk),
osd_op);
} else {
ceph_abort();
}
submit_manager.op_submit_finish(op_num);
utime_t end = ceph_clock_now();
logger->tinc(l_filestore_queue_transaction_latency_avg, end - start);
return 0;
}
.......
apply_finishers[osr->id % m_apply_finisher_num]->queue(onreadable, r);
submit_manager.op_submit_finish(op);
trace.event("op_apply_finish");
apply_manager.op_apply_finish(op);
utime_t end = ceph_clock_now();
logger->tinc(l_filestore_queue_transaction_latency_avg, end - start);
return r;
}
// 将数据传入到FileJournal中
void JournalingObjectStore::_op_journal_transactions(
bufferlist& tbl, uint32_t orig_len, uint64_t op,
Context *onjournal, TrackedOpRef osd_op)
{
......
if (journal && journal->is_writeable()) {
journal->submit_entry(op, tbl, orig_len, onjournal, osd_op); // 放入journal队列,等待write线程执行journal写请求
} else if (onjournal) {
apply_manager.add_waiter(op, onjournal);
}
}
void FileJournal::submit_entry(uint64_t seq, bufferlist& e, uint32_t orig_len,
Context *oncommit, TrackedOpRef osd_op)
{
......
{
std::lock_guard l1{writeq_lock};
#ifdef HAVE_LIBAIO
std::lock_guard l2{aio_lock};
#endif
std::lock_guard l3{completions_lock};
#ifdef HAVE_LIBAIO
aio_write_queue_ops++;
aio_write_queue_bytes += e.length();
aio_cond.notify_all();
#endif
// write线程执行完成后,会处理这里的completion
completions.push_back(
completion_item(
seq, oncommit, ceph_clock_now(), osd_op));
if (writeq.empty())
writeq_cond.notify_all();
writeq.push_back(write_item(seq, e, orig_len, osd_op)); // 放入队列,等待write线程执行
if (osd_op)
osd_op->journal_trace.keyval("queue depth", writeq.size());
}
}
- FileJournal写流程通过写线程将数据写入到journal中,并在写入完成后回调
// filejournal写线程的入口函数,这个是单线程运行
void FileJournal::write_thread_entry()
{
.....
// 从队列中获取写入的数据
bufferlist bl;
int r = prepare_multi_write(bl, orig_ops, orig_bytes);
.....
#ifdef HAVE_LIBAIO
if (aio)
do_aio_write(bl);
else
do_write(bl);
#else
do_write(bl);
#endif
complete_write(orig_ops, orig_bytes);
}
dout(10) << "write_thread_entry finish" << dendl;
}
- FileJournal::queue_completions_thru journal:写入后回调 写journal线程通过Filejournal::write_thread完成,流程比较简单,执行完成后,就会调用:
void FileJournal::queue_completions_thru(uint64_t seq)
{
...
list<completion_item> items;
batch_pop_completions(items);
list<completion_item>::iterator it = items.begin();
// journal的一次写可以同时写入多个op请求日志,所以这里是循环处理所有已经完成的op
// 将回调全部放入finisher线程的队列
while (it != items.end()) {
completion_item& next = *it;
if (next.seq > seq) // sequence判断是否已经写入完成
break;
.......
if (next.finish) // 放入finisher队列,等待回调
finisher->queue(next.finish); // finisher线程实际上是JournalingObjectStore中的finisher
......
items.erase(it++);
}
batch_unpop_completions(items);
finisher_cond.Signal();
}
- JournalingObjectStore::finisher 这里的回调就是C_JournaledAhead,然后会执行下面这个函数,主要干两件事情:1)将op放入filestore队列排队 2)将ondisk回调放入FileStore::ondisk_finisher
void FileStore::_journaled_ahead(OpSequencer *osr, Op *o, Context *ondisk)
{
......
queue_op(osr, o); // 将op在filestore层面排队,准备写入文件系统
list<Context*> to_queue;
osr->dequeue_journal(&to_queue); // journal已经写成功,出队列
// journal写好了,数据就真正落盘了,所以执行ondisk回调
// 注意此时数据还未写入文件系统,所以不可读
if (ondisk) {
dout(10) << " queueing ondisk " << ondisk << dendl;
ondisk_finishers[osr->id % m_ondisk_finisher_num]->queue(ondisk); // 放入ondisk_finisher的队列,等待回调
}
if (!to_queue.empty()) {
ondisk_finishers[osr->id % m_ondisk_finisher_num]->queue(to_queue);
}
}
- journal写完成后就是将数据写入到pagecache中: journal是单线程顺序执行的,且每条op请求都有唯一的sequence,使得queue_op一定是按提交时候的顺序调用。 但是同一个PG可能连续提交了很多次op请求,这些请求会放入PG对应的OpSequencer中进行排队,然后同时将OpSequencer放入 op_wq队列等待FileStore::op_tp执行,所以如果PG连续提交请求,OpSequencer会在op_wq中同时出现多次, op_tp中可能多个线程同时获取同一个OpSequencer准备执行写文件系统的操作:
void FileStore::queue_op(OpSequencer *osr, Op *o)
{
// queue_op按提交时候的顺序调用,必然导致属于同一个OpSequencer的OP按照提交顺序
// 在OpSequencer内部排队, 保证了PG内部op的先后顺序
osr->queue(o);
......
}
- FileStore::op_tp,这是写入数据到pagecache的线程,入口函数为 FileStore::_do_op, op 在 PG对应的OpSequencer排队以后,说明PG有OP需要执行,这时候线程池就会对其处理,入口函数:
unsigned FileStore::_do_op(OpSequencer *osr, ThreadPool::TPHandle &handle)
{
wbthrottle.throttle(); // filestore层面writeback的限流
......
// op_tp线程池的多个线程可以并发对同一个OpSequencer执行请求
// 锁保证同一个OpSequencer中(也即PG中)只能有一个OP在执行
osr->apply_lock.Lock();
Op *o = osr->peek_queue(); // 获取一个op
apply_manager.op_apply_start(o->op);
int r = _do_transactions(o->tls, o->op, &handle); // 执行写请求到文件系统
apply_manager.op_apply_finish(o->op);
}
对于这个apply_lock有优化的空间,因为如果多个线程都获得同一个osr时,由于apply_lock的存在造成多个线程都被阻塞了,而造成其他 PG 队列的数据不能被及时处理,可以osr同一时间只能被一个线程获取从而去掉apply_lock 写执行完成后,线程还会执行一个finish函数:
void FileStore::_finish_op(OpSequencer *osr)
{
list<Context*> to_queue;
Op *o = osr->dequeue(&to_queue); // 将op从OpSequencer出队列
osr->apply_lock.Unlock(); // 释放锁,这时候其他线程就可以继续对此QpSequencer执行apply操作
op_queue_release_throttle(o); // 释放filestore的throttle,见queue_transactions
if (o->onreadable_sync) {
o->onreadable_sync->complete(0);
}
if (o->onreadable) {
op_finisher.queue(o->onreadable);
}
if (!to_queue.empty()) {
op_finisher.queue(to_queue); // 放入op_finisher队列,等待执行apply回调,标志数据可读
}
delete o;
}
- FileStore::sync_thread
sync线程实现比较简单,目的是获取一个序列号,保证此序列号之前的数据都已经apply过了,即数据已经在page cache中, 然后执行fsync,更新序列号,这样可以保证此序列号之前的数据已经存入disk中,以后不在需要,journal可以做trim释放空间。
需要注意在获取序列号的过程中,会导致FileStore::op_tp block住,影响apply流程,对性能有损失, 可以适当调整参数filestore_max_sync_interval。有一个潜在问题是,如果长时间不sync,可能会导致执行sync的时候, 整个目录数据过多,导致一次sync时间太长,也可能导致系统内存不足而OOM,这些需要结合kernel参数dirty_ratio 和 dirty_expire_centisecs调优
void FileStore::sync_entry()
{
lock.Lock();
while (!stop) {
......
op_tp.pause(); // 暂停apply线程池的处理
if (apply_manager.commit_start()) { // 如果有新的请求需要commit, 返回true
uint64_t cp = apply_manager.get_committing_seq(); // 获取已经apply过的序列号
......
if (backend->can_checkpoint()) {
......
} else {
apply_manager.commit_started(); // 设置block为false,主要是为journal replay服务
op_tp.unpause(); // 恢复线程池
int err = backend->syncfs(); // 这里会sync osd的整个current目录
err = write_op_seq(op_fd, cp); // 记录下commit的序列号
err = ::fsync(op_fd); // 保证更新序列号的操作落盘
}
apply_manager.commit_finish(); // 完成commit,通知journal
wbthrottle.clear();
......
} else {
op_tp.unpause();
}
......
}
stop = false;
lock.Unlock();
}
bool JournalingObjectStore::ApplyManager::commit_start()
{
bool ret = false;
uint64_t _committing_seq = 0;
{
Mutex::Locker l(apply_lock);
blocked = true; // 这个仅仅为journal replay起作用
while (open_ops > 0) { // 等待其他inflight apply 完成
blocked_cond.Wait(apply_lock);
}
{
Mutex::Locker l(com_lock);
if (max_applied_seq == committed_seq) {
blocked = false;
goto out;
}
_committing_seq = committing_seq = max_applied_seq; // 更新序列号
}
}
ret = true;
out:
if (journal)
journal->commit_start(_committing_seq); // tell the journal too
return ret;
}
这里比较晦涩的地方是,sync线程先pause住FileStore::op_tp线程池,然后调用commit_start(), pause后说明线程池不会再有新的apply请求了,为什么还设置变量blocked为true? 首先,设置这个变量为true,目的是防止继续apply:
uint64_t JournalingObjectStore::ApplyManager::op_apply_start(uint64_t op)
{
Mutex::Locker l(apply_lock);
while (blocked) { // 新的apply操作将会阻塞
blocked_cond.Wait(apply_lock);
}
assert(!blocked);
assert(op > committed_seq);
open_ops++;
return op;
}
其次,有一种特殊情况,即journal在做replay的时候,apply的操作不是在FileStore::op_op线程池内完成, 而是在其他线程调用mount的时候,回放日志完成apply,所以pause op_tp不起作用,停止不了apply操作。 如果回放日志太多或太久,导致sync线程开始工作,那么此时需要将回放日志的线程暂停一下, 以便获取序列号,这时候blocked就起作用了,可以阻塞调用mount的线程,等commit完成后唤醒继续replay。
void JournalingObjectStore::ApplyManager::commit_started()
{
blocked = false; // 设置回false
blocked_cond.Signal(); // 唤醒
}
另外还需要注意,sync线程调用commit_start()是有可能被阻塞的,需要等所有的inflight apply完成, 所以apply完成后会检查是否有blocked,这里和刚才的情况不一样,虽然都是阻塞在blocked变量上:
void JournalingObjectStore::ApplyManager::op_apply_finish(uint64_t op)
{
......
if (blocked) {
blocked_cond.Signal(); // 唤醒sync线程
}
......
}
尾记
转载请注明原地址,冯杰的博客:http://Lfengjie.github.io 谢谢!




